





A-Vibe показала хорошие результаты среди аналогичных моделей в обработке запросов, генерации кода и поддержке осмысленного диалога. Технология уже работает в сервисах Авито, например, помогает продавцам писать продающие описания и быстрее договариваться о сделке в мессенджере. До конца года компания планирует добавить ещё 20 новых сценариев.
«Первое место доказывает, что оптимизированная архитектура и качественные данные могут обеспечить отличные результаты даже при небольшом размере модели. Именно обучение небольшой модели под наши нужды позволяет нам закладывать окупаемость инвестиций: Авито планирует вложить в GenAI около 12 млрд рублей, а заработать более 21 млрд рублей к 2028 году», — отметил Андрей Рыбинцев, старший директор по данным и аналитике Авито.
Результаты A-Vibe
A-Vibe продемонстрировала хорошие результаты в ряде задач различной сложности — от базового понимания текста до продвинутых лингвистических задач, требующих глубокой работы с контекстом.
Некоторые результаты тестирования MERA:
- генерация кода на 25% лучше Gemini 1.5 с 8 млрд параметров;
- ведение диалога на 32% точнее Llama 3.1 с 405 млрд параметров;
- способность анализировать смысл текста на 23% точнее Claude 3.5 Haiku.
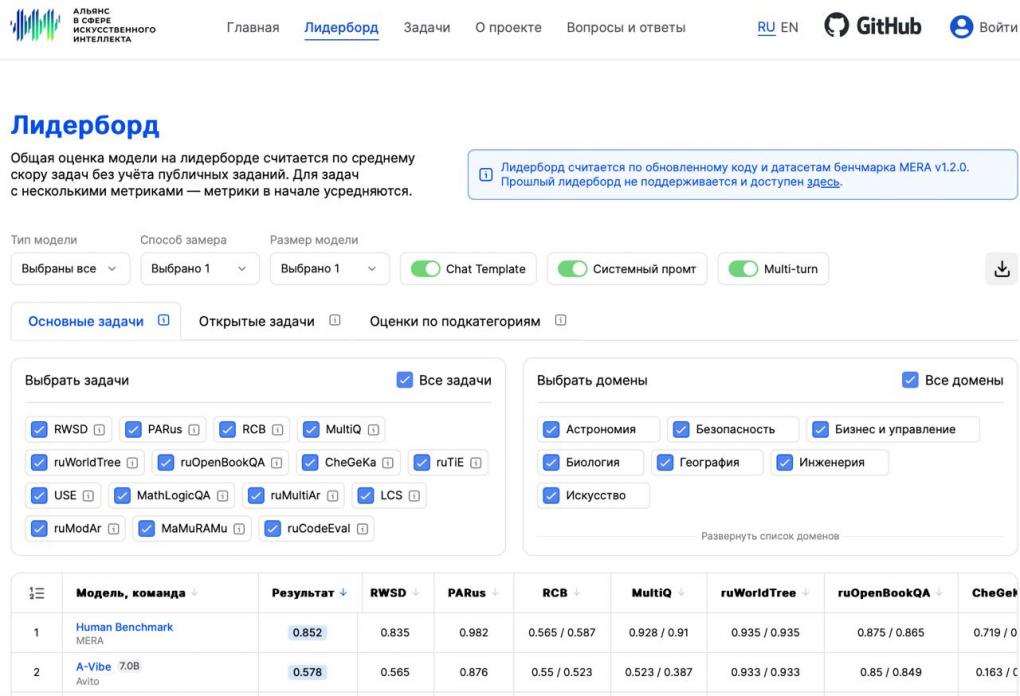
Познакомиться с рейтингом можно на сайте MERA https://mera.a-ai.ru/ru/leaderboard. В фильтре «Размер модели» нужно выбрать «≥5B — 10B», чтобы получить рейтинг среди небольших моделей.
Технические особенности A-Vibe
При разработке генеративных моделей A-Vibe и A-Vision использовалась открытая модель для начального этапа обучения. Однако она имела ограничения в работе с русским языком: модель обучалась на данных более чем 100 языков, при этом русский составлял менее 1% общего объёма данных, из-за чего модель плохо понимала и генерировала текст на русском.
Разработчики модифицировали и провели «русификацию» модели, заменив стандартный токенизатор на собственный, который умеет работать с русским языком. Это дало два ключевых преимущества, выделивших A-Vibe в своём классе:
- модель стала обрабатывать русский текст быстрее до двух раз по сравнению с оригинальной;
- понимание и генерация текста на русском улучшилась.
Анастасия Рысьмятова, руководитель разработки больших языковых моделей «Авито», рассказала, что планируется выпустить модель в открытый доступ. Она отмечает, что это может помочь малому бизнесу внедрять передовые технологии без значительных инвестиций, образовательным учреждениям — создавать прикладные программы, а независимым разработчикам — строить современные сервисы на базе отечественных технологий.
Справка
Бенчмарк MERA — это российский стандарт оценки языковых моделей, разработанный научным сообществом. В рамках замера тестируют понимание русского языка и культурного контекста. Проект поддерживает Альянс ИИ, ведущие индустриальные игроки и академические партнёры, которые занимаются исследованием языковых моделей.
Цифры HUMAN BENCHMARK — это реальные результаты людей. Языковые модели приближаются к этим значениям, но окончательно превзойти человека ещё не смогли.
Фото: «Авито»